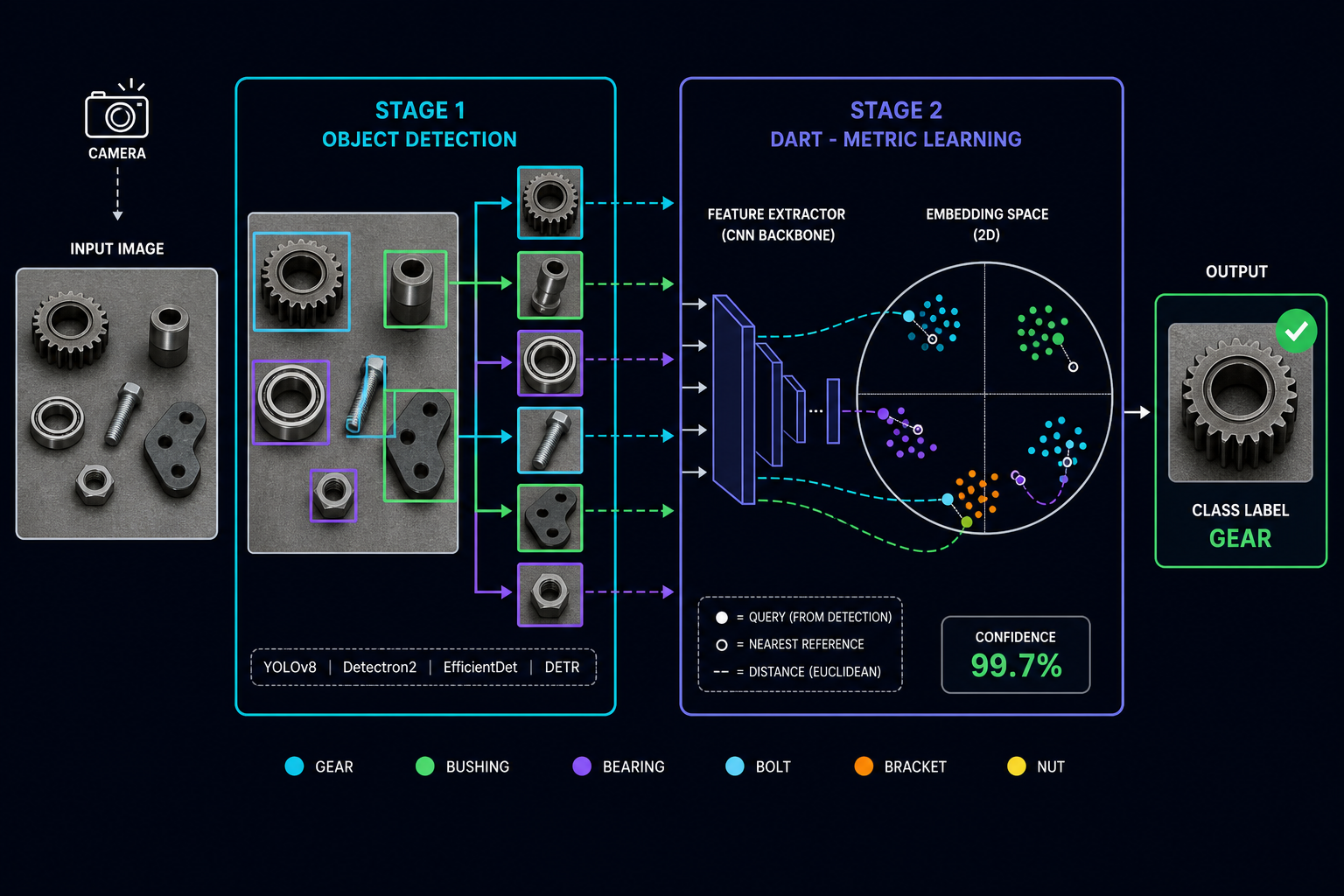
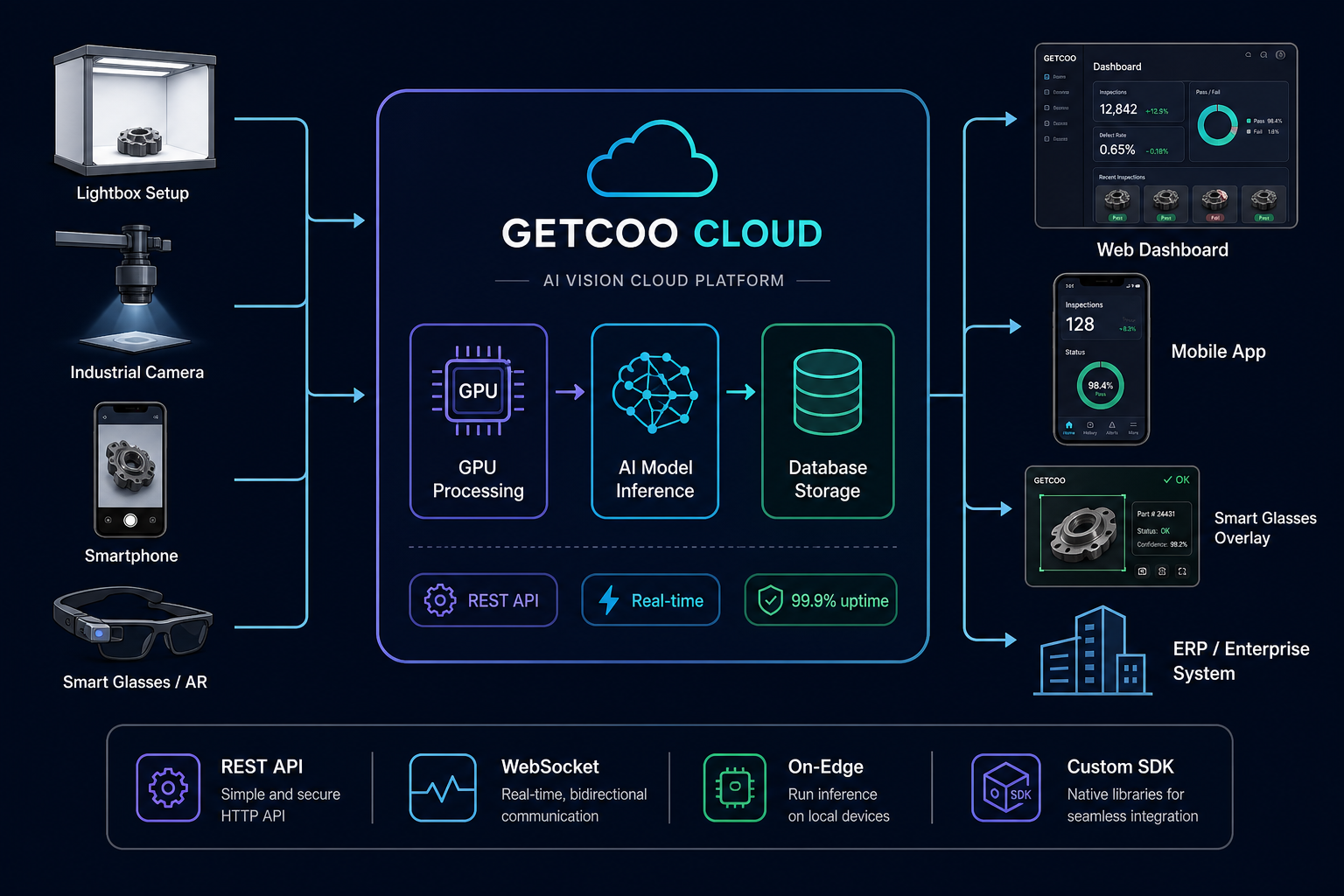
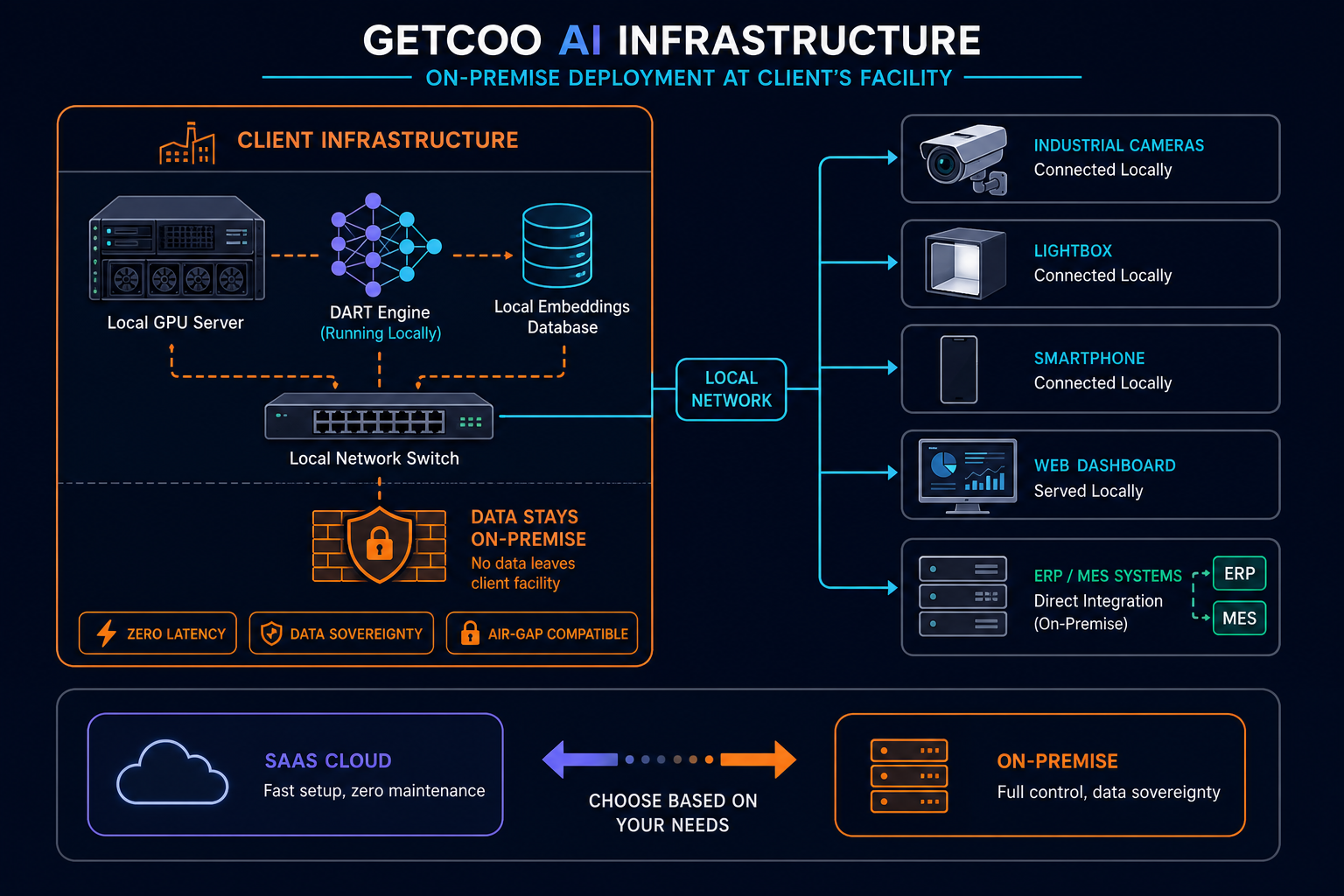
Tecnologia proprietaria
DART — Direct Acquisition
and ReTrieval
Layer proprietario di metric learning applicato on-top a pipeline di object detection (YOLO, Ultralytics, Detectron2, EfficientDet, DETR). Riduce drasticamente i campioni necessari in fase di training e garantisce precisione estrema in inference per l'identificazione visiva.